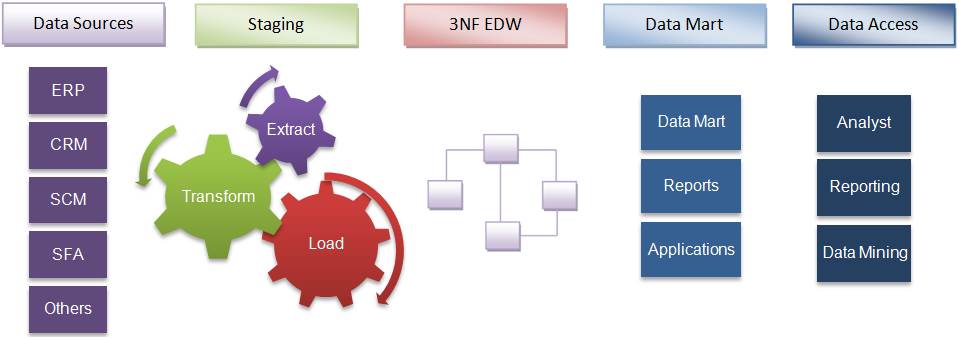
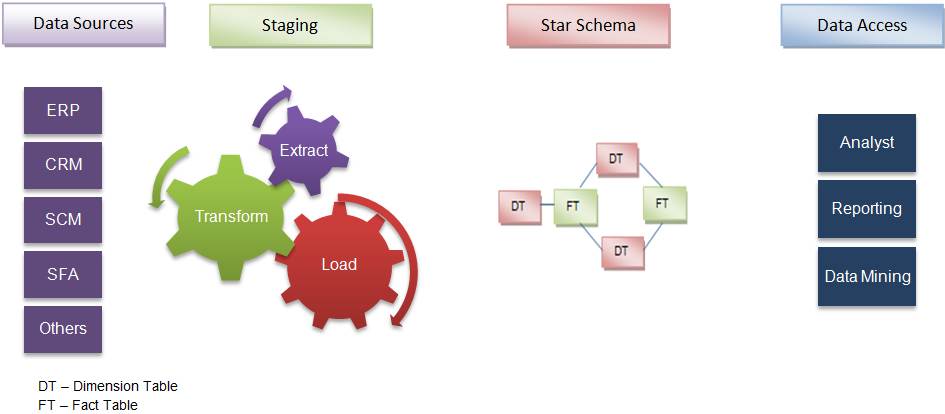
A dynamic SQL in a stored procedure is a single Transact-SQL statement or a set of statements stored in a variable and executed using a SQL command. There may be several methods of implementing this in SQL Server.
"When to Use Dynamic SQL?" We can't definitely say that a Static SQL will meet all our programming needs. A Dynamic SQL is needed when we need to retrieve a set of records based on different search parameters. Say for example - An employee search screen or a general purpose report which needs to execute a different SELECT statement based on a different WHERE clause.
NOTE: Most importantly, the Dynamic SQL Queries in a variable are not compiled, parsed, checked for errors until they are executed.
sp_executesql Vs EXECUTE Command
A dynamically build Transact-SQL statements can be executed using EXECUTE Command or sp_executesql statement.
sp_executesql which is more efficient, faster in execution and also supports parameter substitution. If we are using EXECUTE command to execute the SQL String, then all the parameters should be converted to character and made as a part of the Query before execution. But the sp_executesql statement provides a better way of implementing this. It allows us to substitute the parameter values for any parameter specified in the SQL String. Before getting into the actual example, let me differentiate these two commands with a simple example. Say - selecting a record from the employee table using the ID in the WHERE clause.
The basic syntax for using EXECUTE command:
EXECUTE(@SQLStatement)
e.g.
/* Using EXECUTE Command */
/* Build and Execute a Transact-SQL String with a single parameter
value Using EXECUTE Command */
/* Variable Declaration */
DECLARE @EmpID AS SMALLINT
DECLARE @SQLQuery AS NVARCHAR(500)
/* set the parameter value */
SET @EmpID = 1001
/* Build Transact-SQL String with parameter value */
SET @SQLQuery = 'SELECT * FROM tblEmployees WHERE EmployeeID = ' +
CAST(@EmpID AS NVARCHAR(10))
/* Execute Transact-SQL String */
EXECUTE(@SQLQuery)
The basic syntax for using sp_executesql:
sp_executesql [@SQLStatement],[@ParameterDefinitionList],[@ParameterValueList]
e.g.
/* Variable Declaration */
DECLARE @EmpName AS NVARCHAR(50)
DECLARE @SQLQuery AS NVARCHAR(500)
/* Build and Execute a Transact-SQL String with a single parameter
value Using sp_executesql Command */
SET @EmpName = 'John'
SET @SQLQuery = 'SELECT * FROM tblEmployees
WHERE EmployeeName LIKE '''+ '%' + @EmpName + '%' + ''''
EXECUTE sp_executesql @SQLQuery
/* Variable Declaration */
DECLARE @EmpID AS NVARCHAR(50)
DECLARE @SQLQuery AS NVARCHAR(500)
/* Build and Execute a Transact-SQL String with a single
parameter value Using sp_executesql Command */
SET @EmpID = '1001,1003'
SET @SQLQuery = 'SELECT * FROM tblEmployees
WHERE EmployeeID IN(' + @EmpID + ')'
EXECUTE sp_executesql @SQLQuery
/* Variable Declaration */
DECLARE @OrderBy AS NVARCHAR(50)
DECLARE @SQLQuery AS NVARCHAR(500)
/* Build and Execute a Transact-SQL String with a single parameter
value Using sp_executesql Command */
SET @OrderBy = 'Department'
SET @SQLQuery = 'SELECT * FROM tblEmployees Order By ' + @OrderBy
EXECUTE sp_executesql @SQLQuery
"When to Use Dynamic SQL?" We can't definitely say that a Static SQL will meet all our programming needs. A Dynamic SQL is needed when we need to retrieve a set of records based on different search parameters. Say for example - An employee search screen or a general purpose report which needs to execute a different SELECT statement based on a different WHERE clause.
NOTE: Most importantly, the Dynamic SQL Queries in a variable are not compiled, parsed, checked for errors until they are executed.
sp_executesql Vs EXECUTE Command
A dynamically build Transact-SQL statements can be executed using EXECUTE Command or sp_executesql statement.
sp_executesql which is more efficient, faster in execution and also supports parameter substitution. If we are using EXECUTE command to execute the SQL String, then all the parameters should be converted to character and made as a part of the Query before execution. But the sp_executesql statement provides a better way of implementing this. It allows us to substitute the parameter values for any parameter specified in the SQL String. Before getting into the actual example, let me differentiate these two commands with a simple example. Say - selecting a record from the employee table using the ID in the WHERE clause.
The basic syntax for using EXECUTE command:
EXECUTE(@SQLStatement)
e.g.
/* Using EXECUTE Command */
/* Build and Execute a Transact-SQL String with a single parameter
value Using EXECUTE Command */
/* Variable Declaration */
DECLARE @EmpID AS SMALLINT
DECLARE @SQLQuery AS NVARCHAR(500)
/* set the parameter value */
SET @EmpID = 1001
/* Build Transact-SQL String with parameter value */
SET @SQLQuery = 'SELECT * FROM tblEmployees WHERE EmployeeID = ' +
CAST(@EmpID AS NVARCHAR(10))
/* Execute Transact-SQL String */
EXECUTE(@SQLQuery)
The basic syntax for using sp_executesql:
sp_executesql [@SQLStatement],[@ParameterDefinitionList],[@ParameterValueList]
e.g.
/* Variable Declaration */
DECLARE @EmpName AS NVARCHAR(50)
DECLARE @SQLQuery AS NVARCHAR(500)
/* Build and Execute a Transact-SQL String with a single parameter
value Using sp_executesql Command */
SET @EmpName = 'John'
SET @SQLQuery = 'SELECT * FROM tblEmployees
WHERE EmployeeName LIKE '''+ '%' + @EmpName + '%' + ''''
EXECUTE sp_executesql @SQLQuery
/* Variable Declaration */
DECLARE @EmpID AS NVARCHAR(50)
DECLARE @SQLQuery AS NVARCHAR(500)
/* Build and Execute a Transact-SQL String with a single
parameter value Using sp_executesql Command */
SET @EmpID = '1001,1003'
SET @SQLQuery = 'SELECT * FROM tblEmployees
WHERE EmployeeID IN(' + @EmpID + ')'
EXECUTE sp_executesql @SQLQuery
/* Variable Declaration */
DECLARE @OrderBy AS NVARCHAR(50)
DECLARE @SQLQuery AS NVARCHAR(500)
/* Build and Execute a Transact-SQL String with a single parameter
value Using sp_executesql Command */
SET @OrderBy = 'Department'
SET @SQLQuery = 'SELECT * FROM tblEmployees Order By ' + @OrderBy
EXECUTE sp_executesql @SQLQuery